
「AIの勉強で出てくる『正則化』って、一体なにをコントロールしているの?」
「L1とL2の違いがいつもゴチャゴチャになる……」
「『不要なデータをゼロにする』ってどういうこと?」
機械学習モデルの精度を上げるうえで、誰もが一度はぶつかる壁が「正則化」です。そのなかでも、データをバッサリと間引いてシンプルにしてくれる特効薬が「L1正則化(ラッソ回帰とも呼ばれます)」です。
最大の特徴は、一言でいうと「不要な原因を削って予測を補正する」こと。データが多すぎてAIが混乱(過学習)してしまうのを防ぐため、関係の薄い要素の影響度を完全に「ゼロ」にして、本当に重要なデータだけを厳選してくれる非常に頼もしい技術です。
この記事では、試験のひっかけ問題としても大定番の「L1正則化」の仕組みと特徴を、5枚の図解構成に合わせて分かりやすく解説します!
目次
1.【直感編】L1正則化とは?一言でいうと「不要な原因を削って予測を補正する技術」
2.【位置づけ】過学習を防ぐための補正手法!機械学習におけるマッピング
3.【理論編】どうやって動く?無駄な影響度をゼロに削る3つのステップ
4.【比較編】何が違う?ゼロにする「L1正則化」vs 全体を縮める「L2正則化」
5.【まとめ】これだけは押さえよう!L1正則化の本質と身近な代表例
1.【直感編】L1正則化とは?一言でいうと「不要な原因を削って予測を補正する技術」
まずは、L1正則化(えるわんせいそくか)がどのようなものなのか、直感的なイメージから掴みましょう。

L1正則化とは、一言でいうと「不要な原因を削って予測を補正する技術」です。
たくさんの荷物(データの特徴量)を抱えてフラフラ走っているロボットをイメージしてください。そこへ「L1正則化」と書かれたはさみを持った審判ロボットが現れ、あまり役に立っていない細かな荷物の紐をバツバツと切り落としていきます。荷物がすっきりと軽くなったことで、ロボットがまっすぐ軽快にゴールへ向かって走り出せるようになります。
💡 【ワンポイント】 > 関係の薄いデータを
ゼロにしてモデルを
シンプルにする!
2.【位置づけ】過学習を防ぐための補正手法!機械学習におけるマッピング
次に、L1正則化がデジタル技術の中でどのような位置づけにあるのか、全体マップを見てみましょう。
L1正則化は、教師あり学習のなかで「過学習(過去のデータに一喜一憂して、本番の予測がブレてしまう現象)」を綺麗に防ぐための「正則化」という枠組みの中にあります。
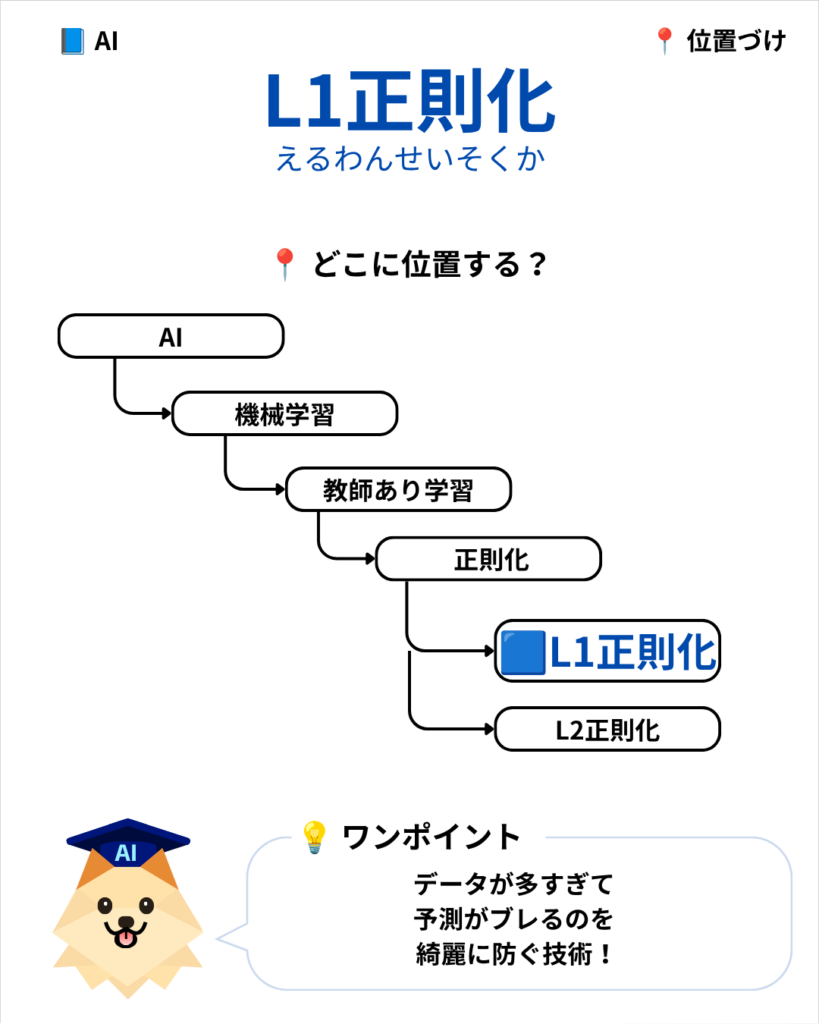
ライバルである「L2正則化」と並ぶ、過学習防止のツートップの片翼です。データが多すぎて予測のブレ(過学習)が起きるのを防ぐために欠かせない技術です。
💡 【ワンポイント】 > データが多すぎて
予測がブレるのを
綺麗に防ぐ技術!
3.【理論編】どうやって動く?無駄な影響度をゼロに削る3つのステップ
L1正則化が動く本質的な目的は、「無駄な影響度をゼロに削る」という点にあります。絶対値の合計を使って大胆にデータを間引くため、次の3つのステップで数式をすっきりさせます。

- ステップ1:ペナルティを与えるロボットが予測の数式を組み立てる際、「使う原因の数(影響度の絶対値の合計)」が増えれば増えるほど、全体のペナルティとして点数が悪くなるという厳しい「罰則ルール」を追加します。
- ステップ2:影響度を削ぎ落とすこの罰則ルールを嫌がった数式は、売上や予測の結果に対して重要度の低い、細かな原因の影響度をどんどん小さくしていき、ついに完全に「0」まで削り込んで消去してしまいます。
- ステップ3:重要項目だけ残す本当に大切な数個の原因だけが手元に残り、余計なノイズ(関係のないデータ)が綺麗に消えた、シンプルで頑丈な予測ルートが完成します。
💡 【ワンポイント】 > 絶対値の合計を使い
大胆にデータを間引き
すっきりさせる!
4.【比較編】何が違う?ゼロにする「L1正則化」vs 全体を縮める「L2正則化」
試験で最もよく出題され、受験者を悩ませるのが「L2正則化」との違いです。この2つの決定的な違いを整理しておきましょう。
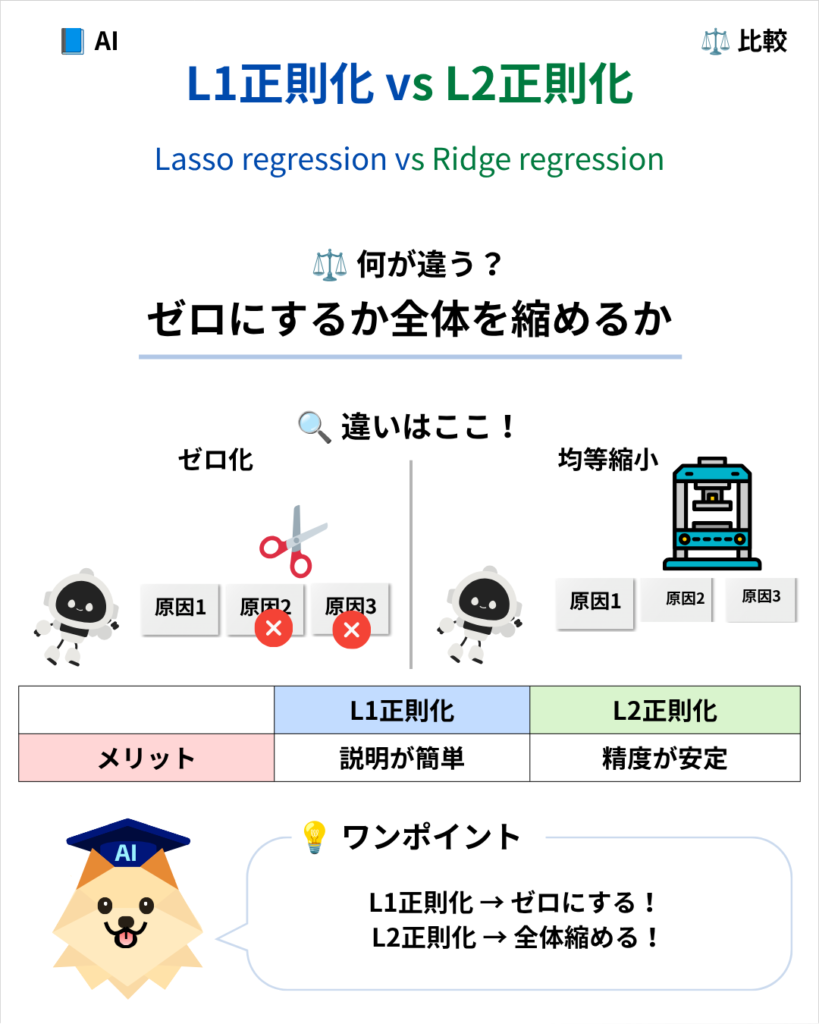
一言でいうと、その違いは「ゼロにするか? 全体を縮めるか?」にあります。
| 項目 | L1正則化 | L2正則化 |
| 削り方 | ゼロにする | 全体的に縮む |
| 残る要素 | 厳選される | 全て残る |
| メリット | 説明が簡単 | 精度が安定 |
L1正則化は、複数の原因のうち「いらない」と判断したものをハサミでパチンと切り落とし、完全に無くしてゼロにするロボットです。要素が厳選されて中身がシンプルになるため、人間に対して「なぜこの予測になったのか」を説明しやすいのが大きなメリットです。一方でL2正則化(リッジ回帰)は、すべての原因を上からぎゅっと均等に押し潰し、どれもゼロにはせず全体的に小さくまとめて、予測の精度を安定させるのが得意です。
💡 【ワンポイント】 > L1正則化 ➡ ゼロにする!
L2正則化 ➡ 全体縮める!
5.【まとめ】これだけは押さえよう!L1正則化の本質と身近な代表例
最後に、今回学んだL1正則化の要点を振り返りましょう。
まずはここだけ絶対に押さえておけば完璧です!

高度な医療分析や膨大なデータを扱うビジネスでは、以下のような「真の原因を絞り込みたい」場面でL1正則化の代表例がよく使われています。
- 病気の要因特定: 数百から数万種類もある膨大な遺伝子のデータから、特定の病気に「本当に関係している数個の遺伝子」だけをL1正則化で浮き彫りにする医療AI技術。
- 売上分析の厳選: 天気、曜日、気温から「店員の服の色」まで、無数にあるデータの中から、売上に直接関係している真の原因だけを綺麗に絞り込むマーケティング分析。
- 画像のノイズ消去: 写真や画像の背景にある細かなゴミや、関係のないドットの影響力を完全にゼロにして、主役である被写体の輪郭をはっきりさせる画像処理技術。
💡 【ワンポイント】 > L1正則化とは「余計な要素を学習から削り、過学習を防いで正しく推論させる手法」
L1正則化の本質は、数式に「要素が増えるとペナルティ」というルールを与えることで、重要度の低いお荷物データを完全に「ゼロ」へ落とし込み、モデルを身軽にする点にあります。試験対策としては、L2正則化とは違い「不要な要素を完全にゼロにして特徴量を厳選する効果(スパース性)があること」をしっかりと頭に入れておきましょう!
関連用語はこちら
👉 【G検定・ITパス】L2正則化(Ridge)とは?直観・理論の2つの視点でわかりやすく図解!
👉 【G検定・ITパス】過学習とは?直観・理論の2つの視点でわかりやすく図解!
📚 このテーマをもっと学びたい方へ
さらに理解を深めたい方には、G検定の公式テキストがお薦めです!

コメント