
「ホールドアウト法って、データを分けるだけで何がすごいの?」 「過学習を見抜く仕組みがイマイチ分からない…」
AIやデータサイエンスの学習中、モデルの評価方法で悩んでいませんか?
この記事では、G検定やITパスポート、DS検定などIT資格すべてで最頻出となる「ホールドアウト法」の仕組みを、【直感編】【理論編】の2枚の図解を使って、誰よりも分かりやすく解説します!
【直感編】ホールドアウト法とは?「過去問」と「模試」に分ける鉄則 まずは、数式なしでイメージを掴みましょう。ホールドアウト法は、手元のデータを「練習用」と「本番用」に最初から分けておく、AIの超王道テスト方法です。

ホールドアウト法の定義やデータの分割を試験に例えた直感図解 AIが過去問を丸暗記してカンニングするのを防ぐため、本番用の問題(テストデータ)は最初から別箱に隠しておくのが鉄則です。
- 訓練データ(過去問): AIがパターンの勉強(学習)をするために使うメインデータ。
- テストデータ(模擬試験): AIの学習には「絶対に絶対に使わず」、最後の最後まで隠しておくデータ。
この「隠しデータ」で点数を測るからこそ、AIが過去問を丸暗記していないか、本当の実力(汎化性能)を厳密にチェックできます。
【理論編】ホールドアウト法の仕組みとメリット 次に、仕組みの面から「なぜ過学習を見抜けるのか」を深掘りします。
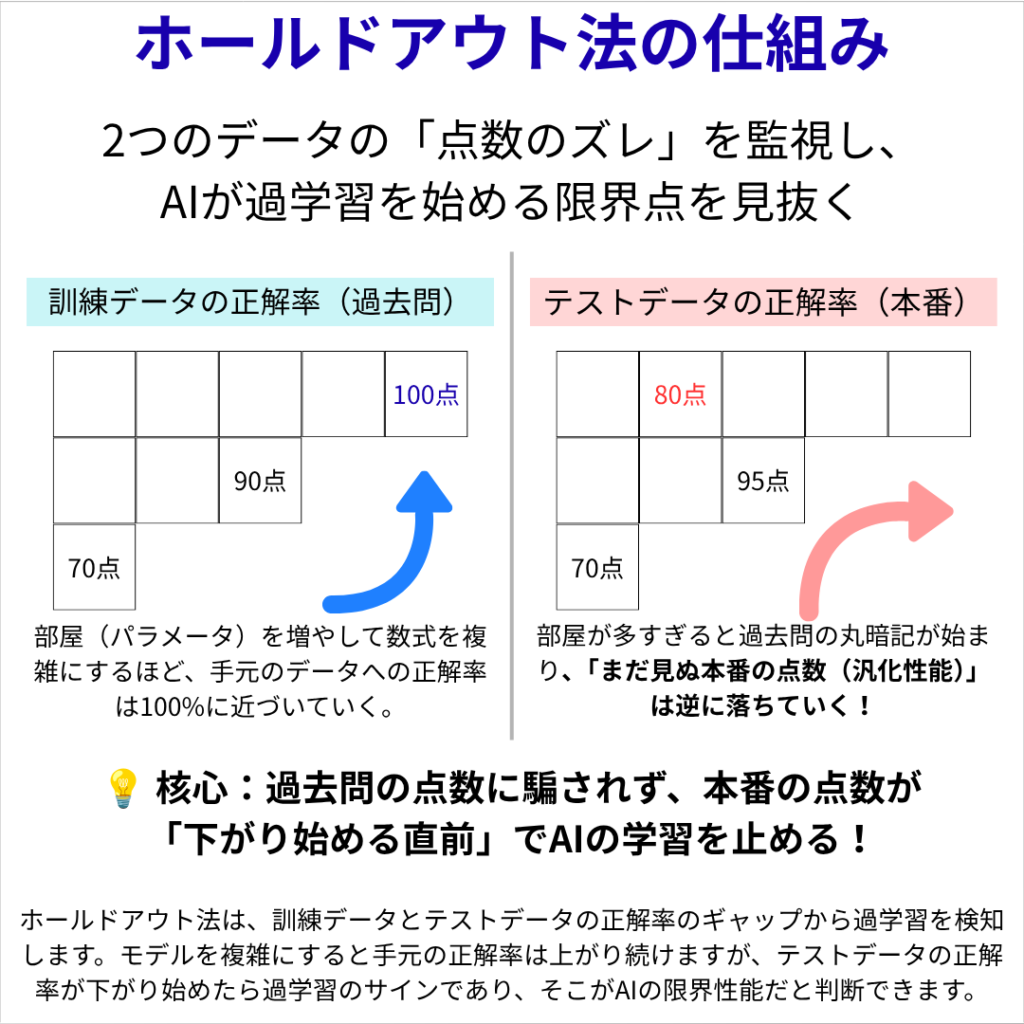
ホールドアウト法が正解率のギャップから過学習を検知する仕組みを解説した理論図解 ホールドアウト法の核心は、2つのデータの「点数のズレ」をリアルタイムで監視することにあります。
AIのモデルを複雑にする(数式の中にパラメータという部屋を増やす)ほど、過去問(訓練データ)への正解率は100%に近づいていきます。しかし、部屋が多すぎるとAIは「応用ルール」を学ぶのをやめ、答えそのものを丸暗記し始めてしまいます。
- 過去問の点数: 部屋を増やすほど100点に向かって上がり続ける。
- 本番の点数: ある限界点を超えると丸暗記のせいで逆に落ちていく!
過去問の点数に騙されず、本番の点数が「下がり始める直前」でAIの学習を止める。これこそが、ホールドアウト法の真の役割であり、過学習のサインを見抜く仕組みです。
【5大試験対策】試験に出る重要キーワードまとめ 5大IT資格を制覇した合格者の視点から、試験で狙われるポイントを整理しておきましょう。
- 汎化性能(はんかせいのう): まだ見ぬ本番データ(未知のデータ)に対して、どれだけ正しく予測できるかという「本番への強さ」のこと。
- 訓練データ / テストデータ: ホールドアウト法で分割されたそれぞれのデータ名。テストデータは「評価データ(検証データ)」と呼ばれることもあります。
- 過学習の検知: 訓練データとテストデータの正解率のギャップ(乖離)から、AIが丸暗記を始めた限界性能を暴く能力。
まとめ:直感と理論で覚えるホールドアウト法 ホールドアウト法は、「カンニング(丸暗記)を防ぐため、本番用のデータは最初から別箱に隠してテストする超王道の評価技術」です。
過去問の点数の伸びに騙されず、本番の点数が下がる直前を見極めることで、本当に賢いAIを作ることができます。
ホールドアウト法は完璧に見えますが、実は「データ数が少ないと評価が不安定になる」という弱点があります。次回は、その弱点を美しく克服するために生まれた「交差検証(クロスバリデーション)」について図解します!ぜひまたチェックしてください。


コメント